Research Projects and Datasources
2017 - Offending Statements / Hate Speech towards Foreigners
Please cite the following paper when using this dataset:
Bretschneider, U.; Peters, R. (2017): Detecting Offensive Statements towards Foreigners in Social Media. In: Proceedings of the 50th Hawaii International Conference on System Sciences (HICSS), Hawaii, USA, January 4-7, 2017.
We constructed three datasets by accessing publicly available Facebook pages. We crawled Facebook posts including the comments published in response to them from the Facebook pages “Pegida” (dataset 1), “Ich bin Patriot, aber kein Nazi” (“I’m a patriot, not a nazi”) (dataset 2) and “Kriminelle Ausländer raus” (“Criminal foreigners get out”) (dataset 3). Further details are described in the publication above. We anonymized the usernames by applying a hash function on each username (including the plaintext).
The datasets are available in two formats:
The database schema is depicted below:
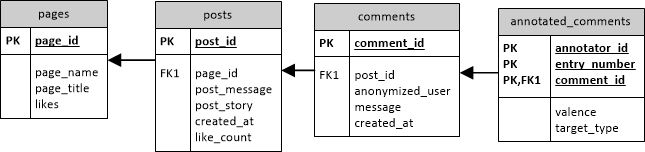
Table "pages" contains the three selected Facebook pages including the crawled posts and their comments. Table "annotated_comments" contains the expert annotations:
- The field annotator_id represents annotator 1 and 2
- For each comment multiple annotations are possible, each annotation has a corresponding entry_number
- The field "valence" represents the perceived severity
- valence = 1: moderately offending
- valence = 2: clearly to substantially offending
- The field "target type" represents the target class
- target_type = 1: no target at all
- target_type = 2: foreigner or refugee
- target_type = 3: politicians or government
- target_type = 5: other target
- target_type = 6: unknown target
- target_type = 7: community of the Facebook page
- target_type = 8: press
Each annotation indicates an Hate Speech case, all other comments are neutral.
2016 - Cyberbullying Datasets (WoW Forum and LoL Forum)
Please cite the following paper when using this dataset:
Bretschneider, Uwe and Peters, Ralf, "DETECTING CYBERBULLYING IN ONLINE COMMUNITIES" (2016). Research Papers. Paper 61. http://aisel.aisnet.org/ecis2016_rp/61
We collected two datasets from the World of Warcraft (dataset 1) and Leage of Legends (dataset 2) forum. Dataset 1 contains 20 topics for each dataset. The annotation is performed by three human experts labeling each message in these topics. Online harassment cases are annotated as a tuple of the form: (offender, victim, message). We only include tuples in the final dataset, if there is a consensus between at least two of the three annotators excluding the remaining tuples. The resulting dataset 1 contains 16975 messages with 137 harassment cases and dataset 2 contains 17354 messages with 207 harassment cases.
We anonymized the usernames by employing a hash function on each username for the purpose of the publication. However, we evaluated our approach on the original data still containing spelling mistakes and abbrevations. These errors were manually removed by a human expert during the anonymization process and thus an evaluation on the anonymized dataset should yield better results compared to the original dataset.
The database schema is depicted below:
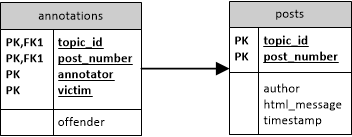
Each annotation indicates an Online Harassment case, all other messages are neutral.
2014 - Online Harassment Datasets (Twitter)
Please cite the following paper when using this dataset:
Bretschneider, U.; Wöhner, T.; Peters, R. (2014): Detecting Online Harassment in Social Networks. In: Proceedings of the 35th International Conference on Information Systems (ICIS 2014), Auckland, New Zealand, December 14-17.
We collected two datasets from the Twitter public stream between 2012-10-20 and 2012-12-30. The main dataset contains 5362 english Twitter messages. The messages were labeled by three annotators. Spam, empty and Re-Tweets (RT) were filtered. The dataset consists of 220 Online Harassment and 5162 neutral messages. The school dataset contains 194 Online Harassment and 2599 neutral messages.
The datasets are available in two flavours: as MySQL database dump or CSV file.
Since the Twitter terms-of-service only allow the distribution of user-IDs and tweet-IDs, we removed the content of the tweets. However, the content can be reconstructed by using the Twitter-API.
MySQL Database
The tables "main_labels" and "school_labels" contain the labels collected from the three anotators. The labels are stored in the column "bullyLabel". This attribute has the value 0 for neutral messages and 1 for Online Harassment messages.
CSV File
The CSV File is a flat copy of the database with a header.